
为什么我们对工程团队的提示缓存感到兴奋


Anthropic 推出的提示缓存,也被称为上下文缓存,继 DeepSeek 和 Google 等提供商推出类似功能后,最近受到了广泛关注。在 Continue,我们尤其对它对工程团队的潜在影响感到兴奋,因为提示缓存可以显著降低成本和延迟。然而,要充分实现这些益处,团队需要在缓存哪些上下文以及如何在提示中进行缓存方面达成一致。
提示缓存如何工作
当大语言模型 (LLM) 回答您的问题时,它们分两部分进行:处理输入 token 和按顺序生成输出 token。
同样的输入 token 经常被传递给模型的多个提示。例如,如果您使用带有多个示例或冗长系统提示的提示模板,那么为每个请求重新处理这个相同的上下文是浪费的。
这就是提示缓存发挥作用的地方。提示缓存通过允许开发者指定经常使用的上下文块进行缓存,从而减少了第一步——处理输入 token 的工作量。
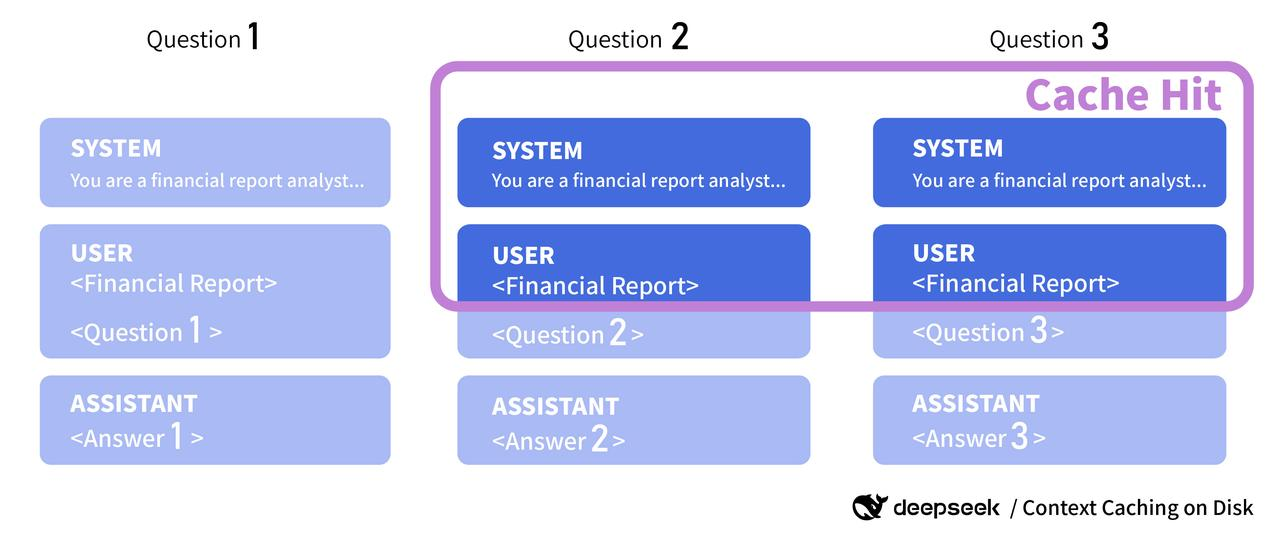
更准确地说,缓存的不是实际的上下文,而是模型处理给定上下文后的状态。为了使提示缓存有效,它必须是一个完美的前缀匹配。
编程助手的用例
那么,我们知道通过提示缓存有可能显著降低成本和延迟。但这这对 AI 代码助手的最终用户来说,又能带来哪些新的使用场景呢?
- 多示例提示 (Many-shot prompting):包含大型示例集(10 个以上)可以成为模型微调的有效替代方案。查看此推文 by Alex Albert,Anthropic 的 DevRel,以获取更多灵感。
- 改进的自动补全和代码库检索:这可以通过传递代码库中顶级代码符号的“摘要”来实现,例如使用仓库映射(repository map)。
- 与文档对话:不仅仅是通过语义搜索检索到的代码片段,还可以是整个文档集。
如何为您的团队最大化提示缓存的效益
上述所有示例贯穿的一个关键主题是,需要让团队就一组共享的缓存上下文达成一致。如果每个开发者使用的示例集、仓库映射或文档版本略有不同,您将无法获得提示缓存带来的成本和延迟节省。
在 Continue,我们将`.prompt 文件`视为实现这一一致性的强大工具。Prompt 文件是一种轻松构建和跨团队共享提示的方式,它们包括配置模型参数、设置系统消息、提供示例以及包含文档等额外上下文的功能。
构建共享的 Prompt 文件库使团队能够标准化处理测试和代码审查等常见任务的方法,并更有效地利用缓存提示。通过确保这些领域的一致性,您将增加缓存命中率,降低成本并最大程度减少延迟。
使用 Continue 尝试提示缓存
第一步,我们已为 Anthropic 启用了系统消息的提示缓存支持。DeepSeek 会自动执行提示缓存,我们计划在不久的将来推出对 Google 的支持。
我们创建了一个示例提示,其中包含 Anthropic 博客文章公告作为系统消息。**您可以在此处下载该提示**,并将其添加到项目中的 `.prompts/` 文件夹中使用。
最后,您需要将**Anthropic 模型配置** 更新为 `\"cacheSystemMessage\": true`
{
"models": [
{
// Enable prompt caching
"cacheSystemMessage": true,
"title": "Anthropic",
"provider": "anthropic",
"model": "claude-3-5-sonnet-20240620",
"apiKey": "YOUR_API_KEY"
}
]
}
要尝试,请在聊天面板中输入 `/claude-prompt-caching`,然后提出一个问题,例如“输入 token 的定价是多少?”。
特别感谢**@BasedAnarki** 贡献了这项工作的初步草稿。
展望未来
提示缓存在团队中既最有效,也最难协调。
展望未来,我们正在探索多种方法来应对这些挑战。有前景的开发领域包括:将共享**仓库映射**与本地开发更改集成的方法,增强**Prompt 文件**以支持用户指定的缓存块,以及针对多轮对话的自动缓存。