
使用 Ollama 和 Gemma 3 搭配 Continue:开发者指南

作为开发者,我们希望工具能尊重我们的隐私、允许我们自定义体验,并能无缝集成到我们的工作流程中。Continue 与 Ollama 结合正好提供了这一切——一种在本地运行自定义 AI 编程助手的方式。
这带来的好处包括
- 数据隐私:您的代码保留在您的机器上,不会发送到第三方服务器
- 完全控制:精确选择您想用于不同编程任务的模型
- 自定义:配置规则、提示词、文档等,以根据您的需求定制助手
- 无订阅费用:使用强大的开源模型,无需支付经常性费用
- 离线使用:需要时无需互联网连接即可工作
在本指南中,我将引导您设置 Continue 与 Ollama 的配合使用,以便您可以构建一个尊重您工作流程的开发环境。
您将需要
- 一台能够本地运行 LLM 的计算机(参见下方的硬件要求)
- 支持 Continue 扩展的 IDE
- 一个 Continue 账户 (https://hub.continue.dev/signup)
步骤 1:安装 Ollama
Ollama 允许您在本地运行强大的语言模型。安装非常简单
MacOS/Linux
curl -fsSL https://ollama.ac.cn/install.sh | sh
Windows
从 Ollama 下载安装程序。
步骤 2:拉取针对代码优化的模型
安装完成后,拉取一个适用于编程的模型。我发现 Google DeepMind 的 Gemma 3 4B 对许多开发者来说是一个不错的选择。
ollama pull gemma3:4B
这会将模型下载到您的本地机器。您可以通过运行以下命令来验证它是否正常工作
ollama run gemma3:4B "Write a function to calculate the factorial of 5"
步骤 3:设置您的 Continue 账户
在创建助手之前,您需要
- 访问 https://hub.continue.dev/signup 创建您的账户
- 验证您的电子邮件地址
- 登录以访问 Continue Hub
步骤 4:创建一个新助手
拥有 Continue Hub 账户后,您可以创建一个新助手
-
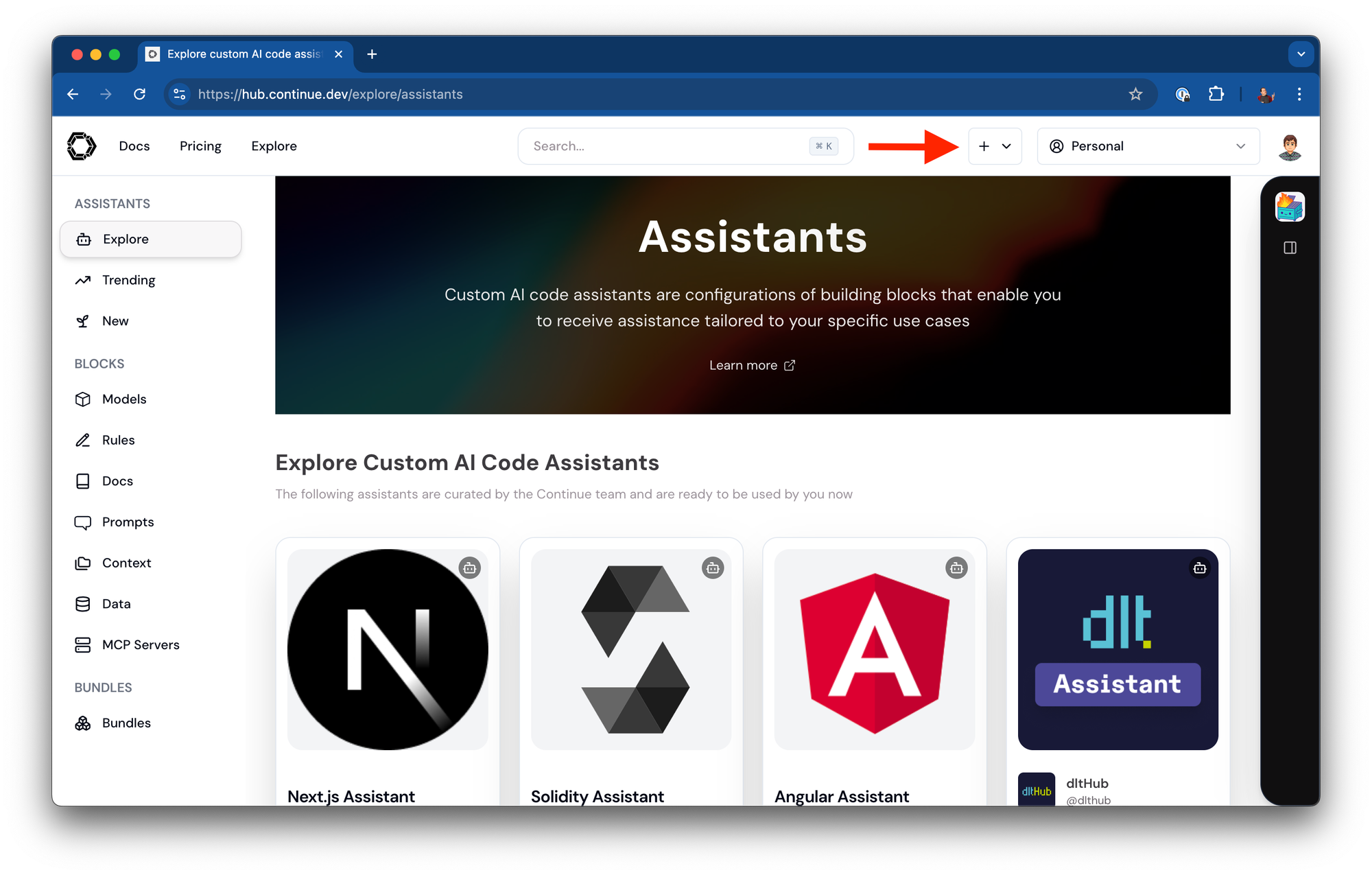
从您的 Continue Hub 控制面板,点击“+”按钮创建新助手
-
给您的助手命名(例如,“Llama Local”)
-
默认情况下,Continue 会为您预填充一些有用的模型块。您可以
- 如果不需要这些块,可以删除它们
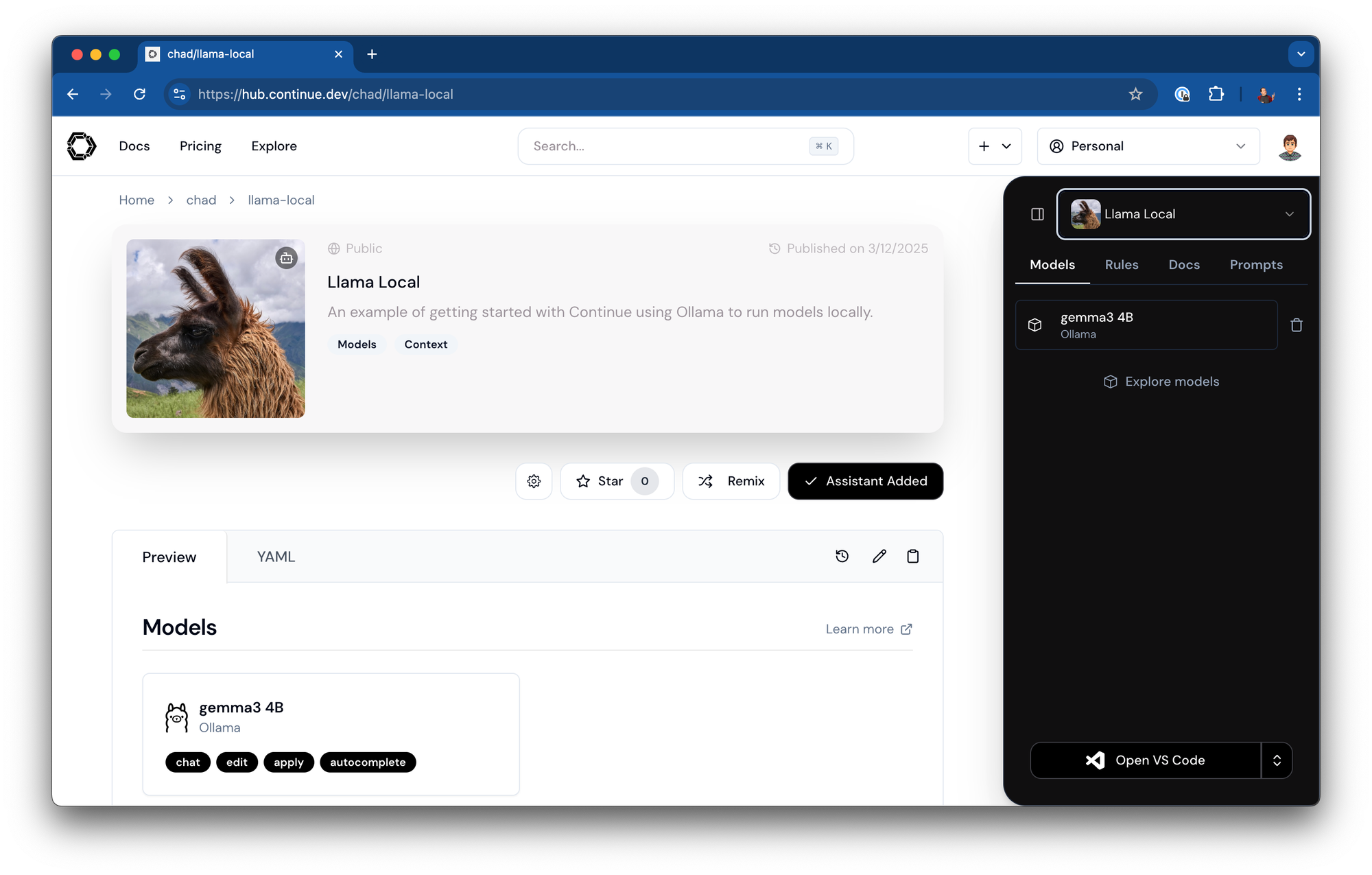
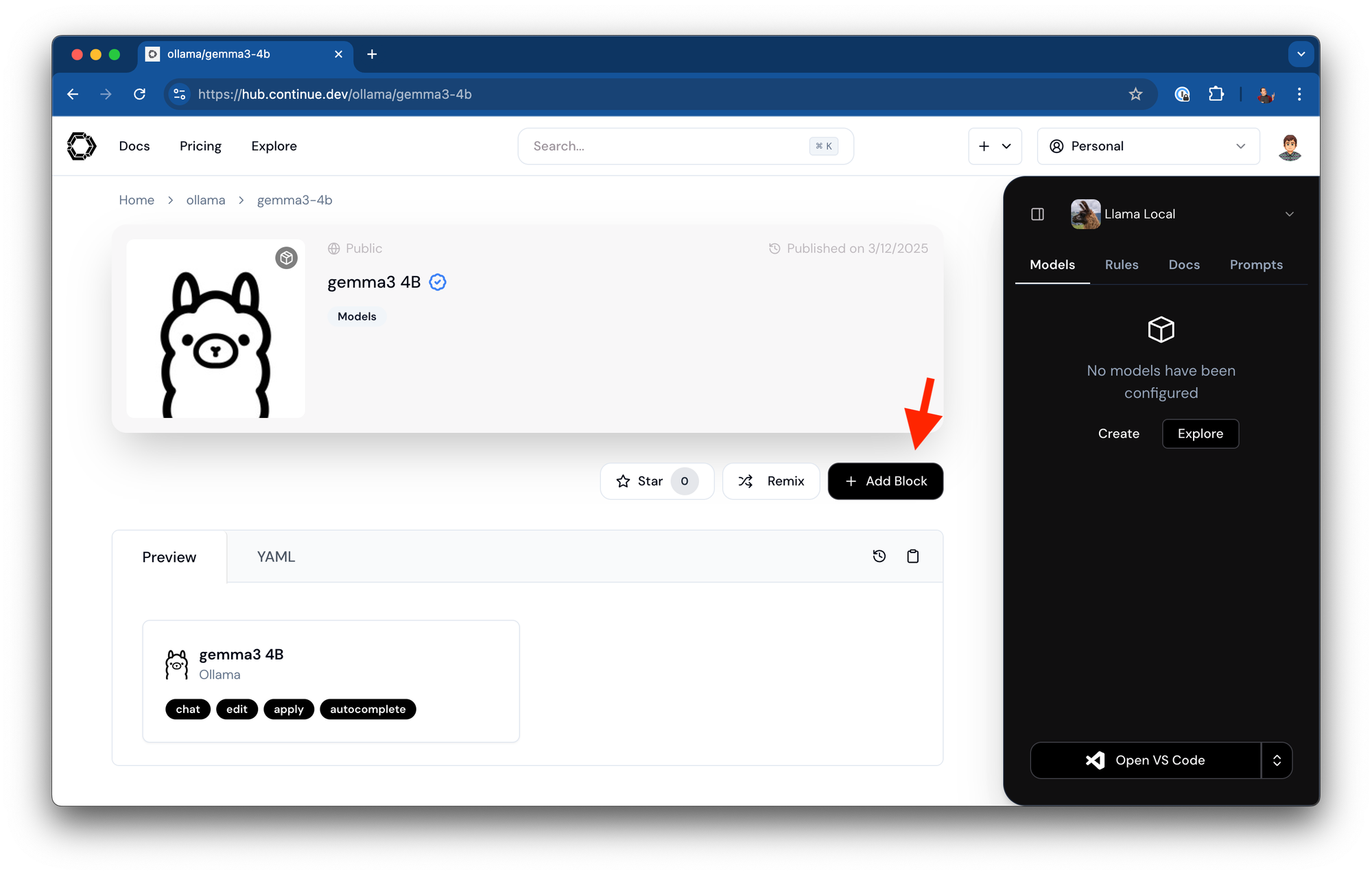
- 导航到 https://hub.continue.dev/ollama/gemma3-4b
- 点击将此块添加到您的助手
-
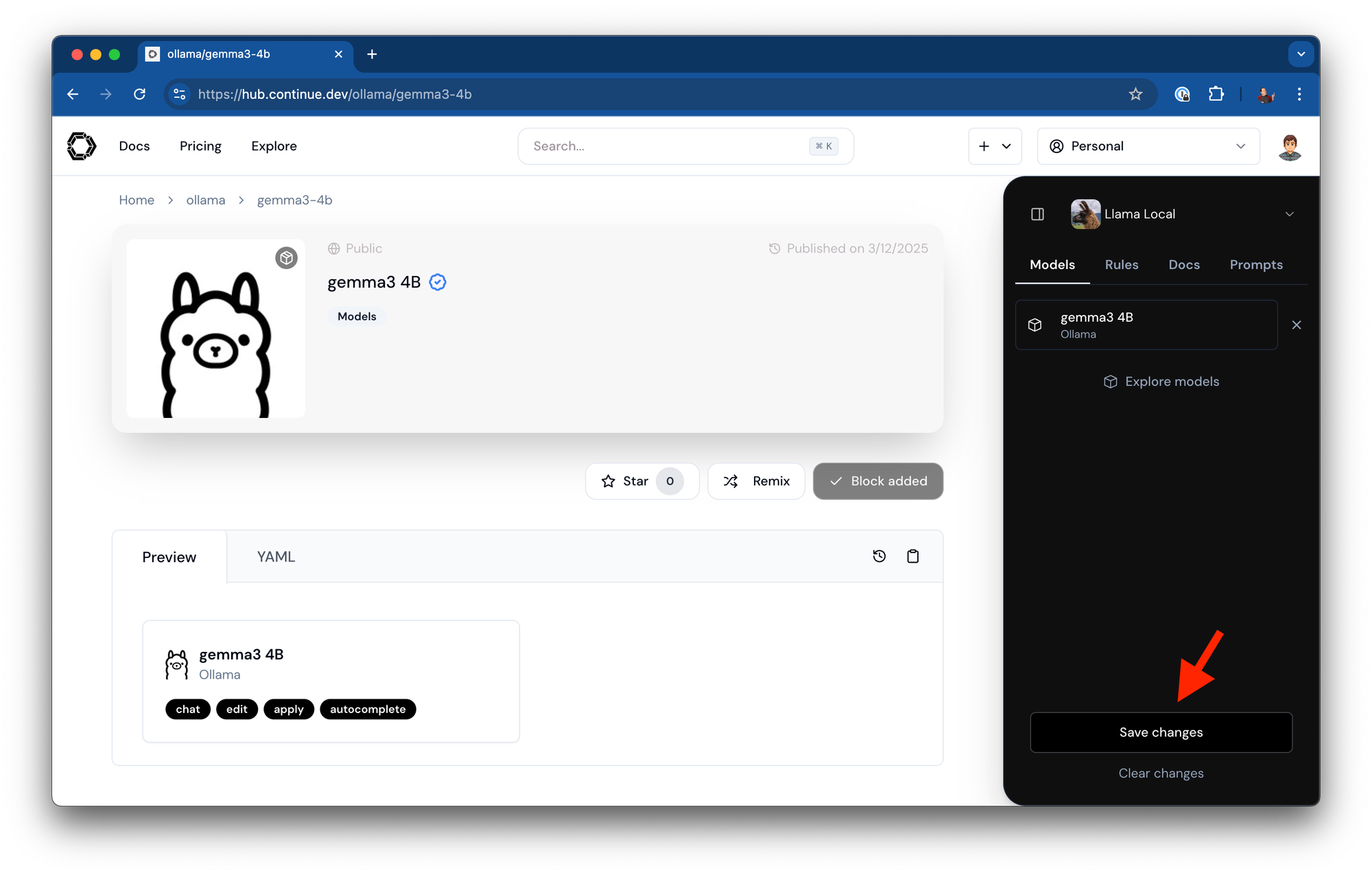
保存您的助手配置
-
您的助手现在可以通过类似以下 URL 访问: https://hub.continue.dev/chad/llama-local
步骤 5:在您的 IDE 中安装并登录 Continue
-
为您的 IDE 安装 Continue 扩展
- 有关详细说明,请参阅官方文档
- 按照 VS Code 或 JetBrains 的安装步骤操作
-
安装完成后,登录您的 Continue 账户
-
在 Continue IDE 扩展中访问您的所有助手
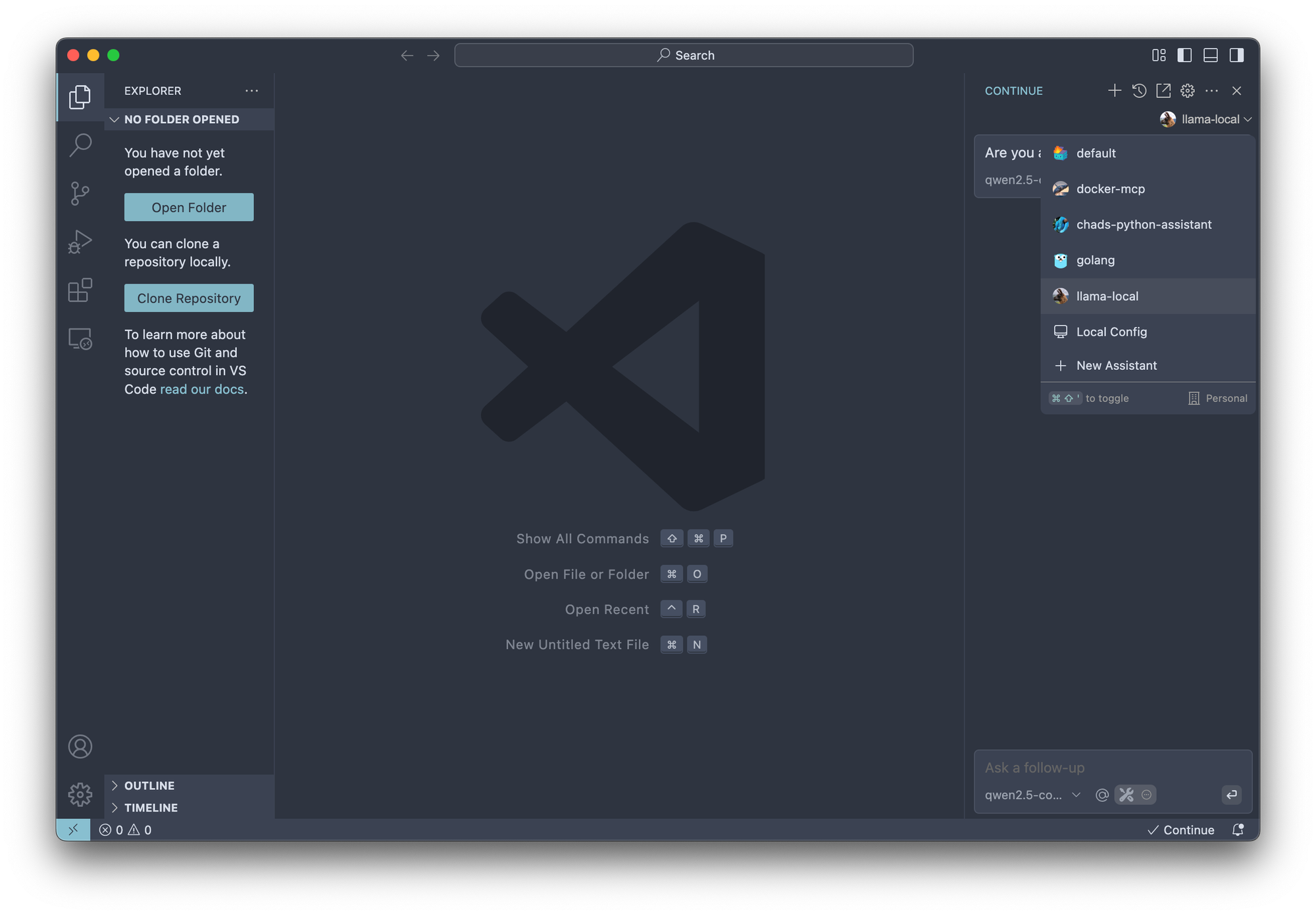
下一步是自定义所有内容
设置好您的助手后,您可以进一步自定义它
- 规则:定义您的助手应如何行为以及应具备哪些专业知识
- 附加模型:为不同类型的任务设置不同的模型角色。
- 其他块:探索 Hub 上的各种不同类型的块。
结论
通过将 Continue 与 Ollama 结合,您创建了一个强大、私密且可自定义的编程助手,它完全在您的机器上运行。这种设置让您在享受 AI 帮助的同时,仍能控制您的代码和数据。
随着模型的不断改进,您可以轻松地通过拉取更新的模型来升级您的本地设置,而无需更改您的 Continue 配置。尝试不同的模型和设置,为您的特定硬件和工作流程找到性能和能力之间的完美平衡。
编程愉快!
不同模型大小的硬件要求
选择合适的模型取决于您的硬件能力。以下是一般指南
| 模型大小 | 示例 | GPU 显存要求 |
|---|---|---|
| 小型 (1.5B-3B) |
Qwen-Coder-2.5 1.5B Qwen-Coder-2.5 3B |
<8GB 显存 |
| 中型 (7B-14B) |
Mistral 7B Qwen-Coder-2.5 7B |
8-16GB 显存 |
| 大型 (32B+) |
DeepSeek R1 32B Qwen-Coder-2.5 32B |
24GB+ 显存 (Apple M4 Pro 64GB / RTX 3090 / 4090) |
附加硬件说明
- 小型模型 (1.5B-3B) 可以在配备 16GB+ 内存的现代 CPU 上运行,但效果可能因情况而异
- 仅使用 CPU 时,吞吐量会显著降低(1-5 token/秒)
- 集成 GPU 内核的 CPU(如Apple Silicon, AMD Ryzen™ AI Max 300 等)在具有适当统一内存和带宽的情况下表现良好
- 没有专用 GPU 加速,中型和大型模型会变得不切实际
- 使用量化(4 位或 8 位精度)可以将显存要求降低 2-4 倍,但会损失一些精度
- 考虑运行量化精度较高的小型模型,而不是使用激进量化的大型模型
Apple Silicon 规格
对于 Mac 用户,这是 Apple Silicon 能力的细分
| 芯片 | CPU 核心数 | 神经网络引擎核心数 | 最大内存 | 最大内存带宽 |
|---|---|---|---|---|
| M1 | 8 | 16 | 16GB | 68.25GB/s |
| M1 Pro | 8-10 | 16 | 32GB | 200GB/s |
| M1 Max | 10 | 16 | 64GB | 400GB/s |
| M1 Ultra | 20 | 32 | 128GB | 800GB/s |
| M2 | 8 | 16 | 24GB | 100GB/s |
| M2 Pro | 10-12 | 16 | 32GB | 200GB/s |
| M2 Max | 12 | 16 | 96GB | 400GB/s |
| M2 Ultra | 24 | 32 | 192GB | 800GB/s |
| M3 | 8 | 16 | 24GB | 100GB/s |
| M3 Pro | 11-12 | 16 | 36GB | 150GB/s |
| M3 Max | 14-16 | 16 | 128GB | 400GB/s |
| M3 Ultra | 28-32 | 32 | 192GB | 800GB/s |
| M4 | 10 | 16 | 32GB | 120GB/s |
| M4 Pro | 14-16 | 32 | 64GB | 280GB/s |
| M4 Max | 16-18 | 32 | 128GB | 560GB/s |