
仍然需要调整 LLM 预设吗?追溯温度、惩罚和采样策略的历史

引言
如今,每个大型语言模型 (LLM) 大致都带有相同的设置,用户可以对其进行调整
- 温度 (temperature)
- 惩罚项 (penalties): 存在惩罚 (presence penalty), 频率惩罚 (frequency penalty) / 重复惩罚 (repetition penalty)
- 策略 (schemes): top-k, top-p
在 r/LocalLlama 中,用户会告诉你 Oobabooga 预设竞技场 如何产生了 Divine Intellect(一个模型预设)的故事,以及这就是你应该使用的预设。但是你真的需要费心去更改 LLM 的默认设置吗?
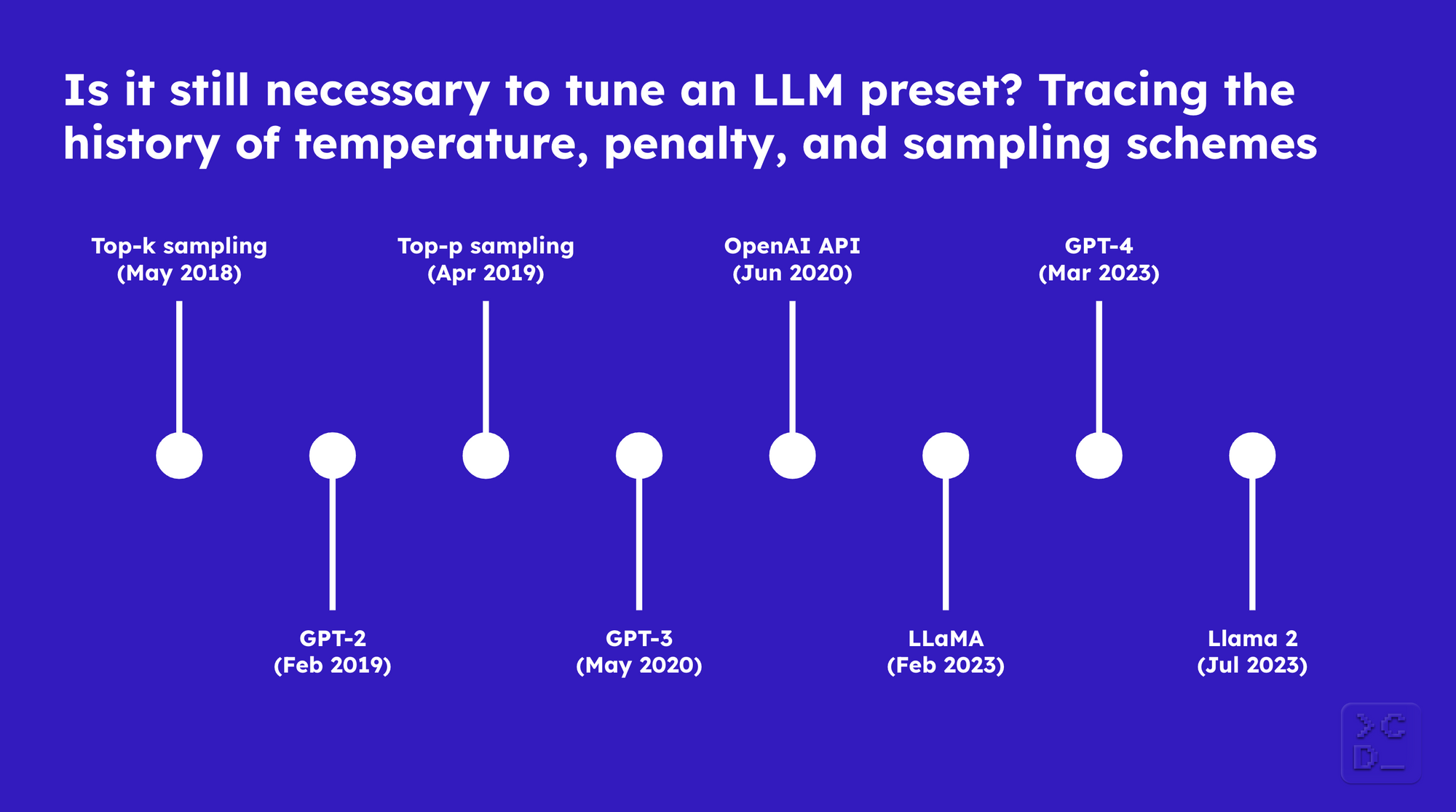
为了弄清楚这一点,我们回顾历史,了解随着语言模型的规模变大和新的开源模型的出现,预设是如何以及为何演变的。
LLM 一次预测一个 token。在预测下一个 token 之前,训练数据词汇表中的每个 token 都有可能被预测。然而,用于预测的实际候选池通常比所有可能的 token 小得多,并且通常会调整概率,以使生成的文本更加连贯和多样化。
温度、惩罚项和采样策略构成了模型预设,它使你能够在预测时调整采样的候选池和每个 token 的概率。以下就是这个预设的由来...
Top-k 采样 (2018年5月)
Facebook AI Research 于2018年5月发表了这篇论文,其中使用了 top-k 随机采样策略。当时,语言模型倾向于很少关注提示。引入 top-k 参数是为了解决以前采样策略容易产生训练集中的常见短语和重复文本的问题。它的工作原理是只从概率最高的 'k' 个 token 中采样下一个 token,其中 'k' 是你预先设定的一个整数。
GPT-2 (2019年2月)
OpenAI 于2019年2月发表了关于 GPT-2 的这篇论文,它生成了令人惊讶的高质量文本段落,例如这篇关于奥维德的独角兽的文章。top-k 采样策略是预设的一部分。模型发布时,温度和重复惩罚也是其中的一部分。温度用于使模型预测低概率 token 的可能性更高或更低,而重复惩罚用于使模型逐字预测相同行的可能性更高或更低。
Top-p 采样 (2019年4月)
华盛顿大学、艾伦人工智能研究所和开普敦大学的研究人员几个月后发表了这篇论文,指出了 top-k 采样的问题,并引入了替代方案:top-p 采样。top-p 采样不是将下一个 token 的样本池限制为固定大小 'k',而是允许你设置一个累积概率阈值,这样采样的候选池可以动态扩展和收缩。这减少了模型在某些情况下产生乱码的倾向,同时又不限制模型在其他情况下的创造力。在后来的 GPT-2 版本中,top-p 采样成为了预设的一部分。
GPT-3 (2020年5月)
OpenAI 发表了关于 GPT-3 的这篇论文。尽管 top-p 采样在 GPT-2 中已经可用,但 GPT-3 论文的作者仍然提到了 top-k。
OpenAI API (2020年6月)
一个月后,OpenAI API 发布,并且一些开发者通过它获得了 GPT-3 的访问权限。在这个 API 中,重复惩罚 (repetition penalty) 被重命名为频率惩罚 (frequency penalty),温度 (temperature) 和 top-p 采样保持不变,并引入了存在惩罚 (presence penalty)。存在惩罚用于使模型讨论新主题的可能性更高或更低。目前尚不清楚 top-k 采样是否曾经可以通过 API 使用,或者何时被移除,但到2021年6月肯定不再是选项了。
LLaMA (2023年2月)
Meta AI(前身为 Facebook AI Research)发表了关于 LLaMA 的这篇论文,并将其作为一个开源模型发布。它远不如许多商业 LLM,但开发者可以在自己的机器上使用它,并在新创建的 r/LocalLLaMA 上开始讨论他们的预设。总的来说,可以使用的预设与 OpenAI API 上的相似,只是频率惩罚通常又被称为重复惩罚,并且也包含了 top-k。
GPT-4 (2023年3月)
OpenAI 于2023年3月发布了关于 GPT-4 的这篇技术报告,OpenAI API 提供了与之前相同的预设选项。但是 GPT-4 生成文本的效果非常好,以至于在许多用例中更改预设变得不那么必要了。到那时,许多人也通过 ChatGPT 界面而不是 API 使用模型,而 ChatGPT 界面不提供调整模型预设的选项。
Llama 2 (2023年7月)
Meta AI 于2023年7月发布了关于 Llama 2 的这篇论文。它相对于第一代 LLaMA 模型有所改进,但仍然不如 GPT-4 等商业模型。它也可能表现出过度重复的问题,因此在使用时调整预设仍然很重要。
结论
通常情况下,通过使用不同的 LLM、提示格式和/或提示内容,比调整模型预设更能塑造模型的响应。但如果你已经优化了这些方面,你也可以考虑更改预设。以下是你要为此提出和回答的问题...
1. 我希望模型的响应更有可能讨论新主题吗?
增加 存在惩罚 (presence_penalty) 可以使每次响应的内容更丰富多样,减少则反之
2. 我希望模型的响应更有可能逐字包含相同的行吗?
增加 频率惩罚 (frequency_penalty) / 重复惩罚 (repetition_penalty) 可以减少每次响应中的重复,减少则反之
3. 我希望模型的响应更有可能包含低概率词语吗?
增加 温度 (temperature) 可以使响应更随机,减少则使其更不随机
4. 我希望模型的响应更有可能只包含高概率词语吗?
增加 top_p 或 top_k 可以使响应更随机,减少则使其更不随机
如果你喜欢这篇博文并想在未来阅读更多关于 DevAI(一群借助 LLM 构建软件的人们组成的社区)的信息,请点击此处加入我们的月度通讯。