
根路径上下文:Continue 自动完成提示的秘密武器


如果你将“根路径”理解为计算机的根目录,请不要担心!Continue 与此无关。我们将分享的是我们收集(和缓存)自动完成上下文的策略,该策略严重依赖于根路径:即从语法树中的一个节点到其根节点的路径。这使得 Continue 看起来能够理解你的整个代码库,而实际上只读取了一小部分。
接近度衡量标准
我们大部分工作的核心挑战是确定要传递给语言模型的最相关上下文。衡量相关度的一种方法是考虑与用户请求的“接近度”,其中可以考虑“接近度”的多种含义:
- 时间上的接近度(包括最近编辑的文件)
- 潜在空间中的接近度(由嵌入的点积确定)
- 代码图中的接近度(包括被周围变量使用的代码定义)
- 抽象语法树(AST)中的接近度(引用树中的父节点或兄弟节点)
对于自动完成功能,我们非常重视提供快速响应(低至几百毫秒)。而且由于生成的代码范围通常很小(小于等于几行),我们不需要将整个代码库作为上下文;只有一小部分是相关的。这意味着我们优化的是更少的输入 token,并尽可能精确地获取来源。
考虑到这一点,潜在空间中的接近度并不是一个好的选择。每次击键时计算嵌入并搜索一个可能很大的索引,性能并不理想,而且从精确度角度来看,这种策略更不太可能有用。
时间上的接近度可能有用,但用户通常可能最近打开了 5 个或更多文件,并且每个文件可能包含数千行代码。最近编辑的范围是另一种可能的策略,我们可能会在未来的帖子中介绍,但仍然不能保证相关。
剩下的两种接近度衡量标准(代码图或 AST)对于自动完成用例来说非常有用。类型定义、函数头、父类或其他附近的符号经常包含准确编写几行代码所需的精确信息。而且由于 AST 和像 Language Server Protocol (LSP) 这样的工具提供的结构,我们可以找到这些信息而无需猜测。
有了精确的上下文来源,我们只需要解决几个问题:1)如何确定哪些定义是最相关的,以及 2)如何使其快速。
理论上的根路径上下文
回顾一下,根路径是 AST 中位于光标位置所在的节点和根节点之间的节点集合。我们依赖的核心观察点是,沿此路径的所有节点都可能包含相关信息。以下面的代码为例:
import convertToAllCaps from "./util";
import convertToAllLowercase from "./util";
type CapitalizationType = "all-lowercase" | "all-uppercase" | "default";
class Person {
name: string;
age: number;
constructor(name: string, age: number) {
this.name = name;
this.age = number;
}
celebrateBirthday() {
this.age++;
}
/**
* Log "Happy {age} birthday {name}!" in desired casing
*/
sayHappyBirthday(capitalizationType: CapitalizationType) {
// [CURRENT CURSOR POSITION]
}
}
光标当前位于一个方法(sayHappyBirthday)内部,该方法位于一个类(Person)内部,该类位于一个文件(Person.ts)内部。这些节点中的每一个都包含有用信息,它们共有的特点是它们都位于树的根部和当前光标位置之间的路径上。
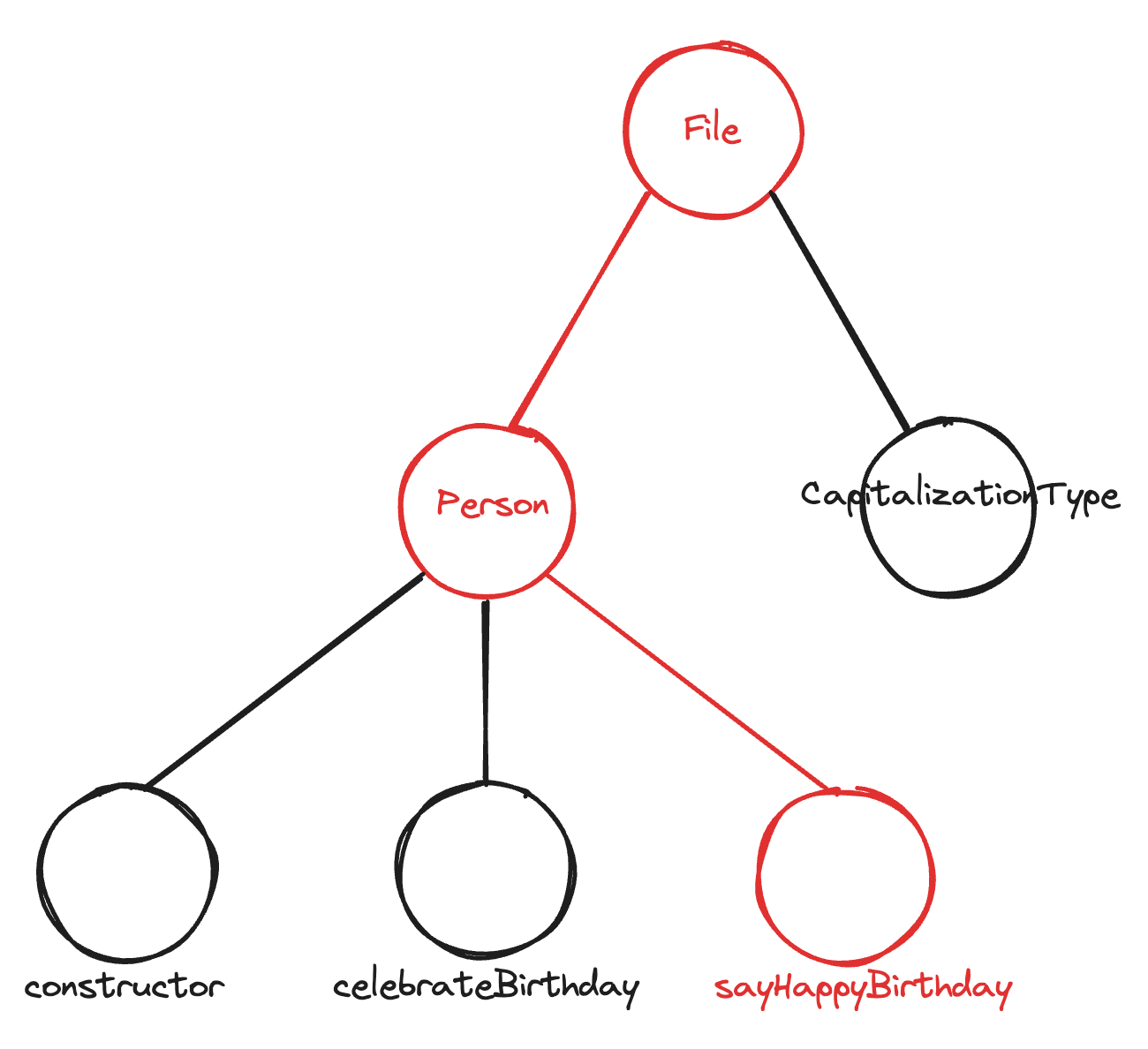
通过使用沿着这条路径累积上下文的简单启发式方法,我们能够收集完成此自动完成所需的所有信息:
- 通过解析
sayHappyBirthday方法所有参数的类型定义,找到CapitalizationType的定义。 - 通过解析
Person类的顶级属性,找到name和age属性。 - 通过解析文件顶部的导入,找到
convertToAllCaps和convertToAllLowercase函数的定义。
尽管这显然是一个玩具示例 [1],但它展示了一个非常有用的启发式方法,类似于开发人员导航代码的方式:我们对自己在文件+语法树中的位置有直观的感觉,并结合“转到定义”来理解周围的代码。
实践中
为了将这个想法转化为可工作的代码,我们采取以下步骤:
- 使用 Tree-sitter 解析文件以获取 AST
- 从根节点开始,下降到包含光标位置的最深节点,记录沿途的每个节点 [2]
- 对于某些重要的节点类型(如函数、类和文件根),运行 Tree-sitter 查询以获取重要子节点(通常是类型注解)的位置
- 使用 LSP 的“转到定义”功能查找每个子节点,递归解析类型定义
例如,在 sayHappyBirthday 方法中,我们将查询找到 CapitalizationType 参数,然后使用“转到定义”查找其来源。现在,行 type CapitalizationType = "all-lowercase" | "all-uppercase" | "default"; 将包含在提示中。
提速
依赖 LSP 的“转到定义”功能的一个问题是我们对其响应速度的控制有限。每种编程语言的 LSP 实现由不同的开发组维护,在大型代码库中的性能可能有所不同,如果我们每次按键都发出请求,这可能会加剧问题,导致明显的延迟。
幸运的是,这种上下文收集策略很容易适用于缓存。假设我们现在想在 celebrateBirthday 方法中做一些更改(允许逆龄生长的抽象当然不是为时尚早)。
直到最低共同祖先,我们已经为每个节点完成了工作(Tree-sitter 查询和 LSP 请求)。因此,唯一需要的请求将是针对 celebrateBirthday 方法的。
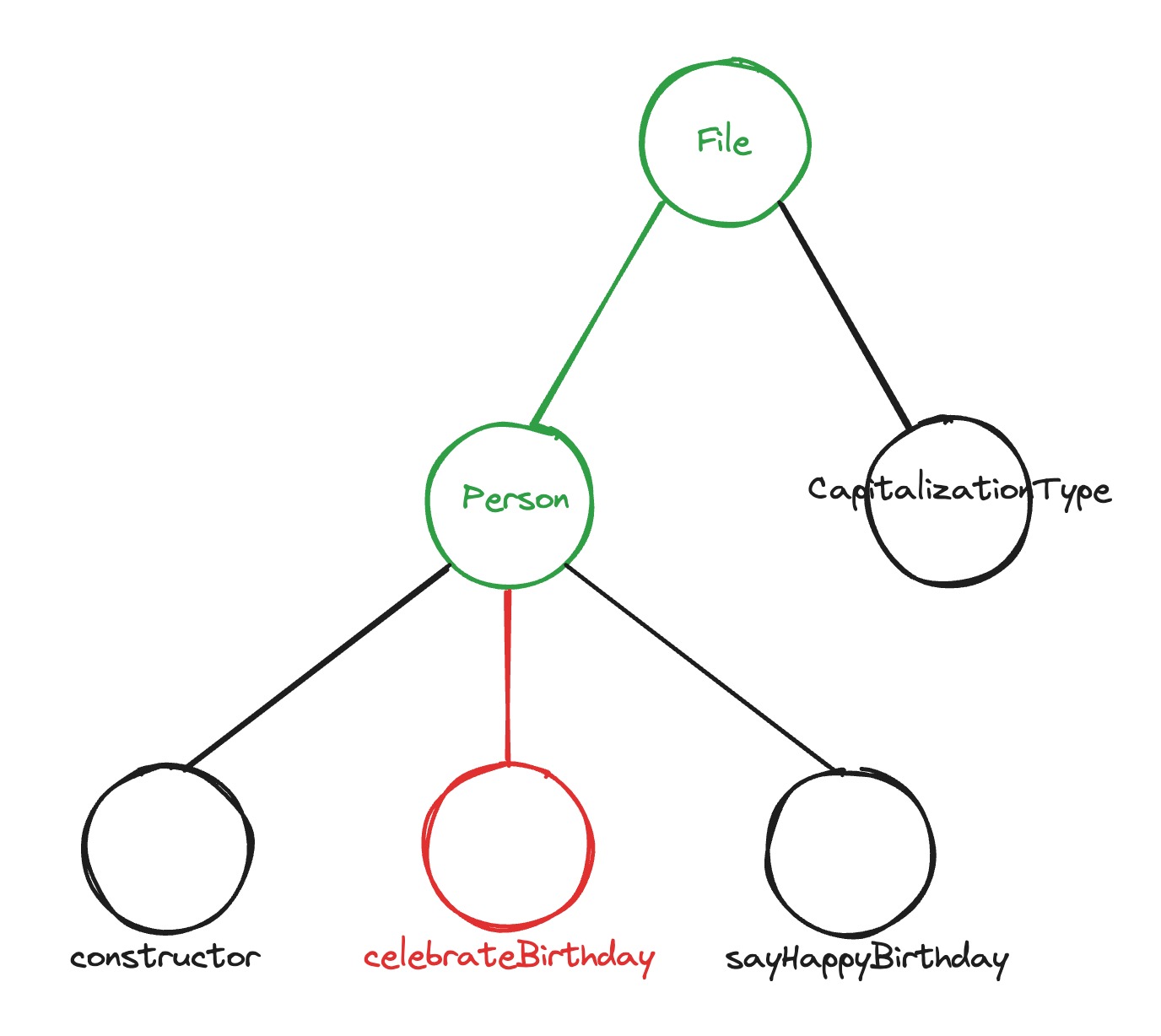
实现这一点并不难。对最近 N 个 LSP 请求进行平面缓存将提供高缓存命中率,原因如上所述:即使在文件中跳来跳去,根路径顶部的大部分内容可能是静态的。如果不是,或者如果切换文件,我们只增加了 O(log(size of AST)) 个额外节点。
后续计划
我们已经开始推广根路径上下文,但仍有许多改进空间。
首先,Tree-sitter 查询需要为每种语言手动编写,我们将把支持的语言从 5 种最常用语言扩展到几十种。
我们尚未实现任何从缓存中撤销上下文的方法。由于最近的更改通常是相关的,我们需要确保不包含过时的类型定义。
最后,这种结构的另一个好处是它可以轻松进行提示缓存。只要我们按照从 AST 顶部到底部的顺序包含上下文,提示的开始部分在不同调用之间将保持不变。
如果您想了解更多,可以阅读自动完成文档或在此处查看原始源代码(它出奇地简洁!)。
注
[1] 由于文件很小,此上下文默认已包含在前缀中。但在更大的文件中,或者如果需要解析定义在其他文件中的更多类型,默认方法将不起作用。
[2] 当光标位于代码符号之间的空白处时,不总是叶子节点。
[3] 在决定直接将其命名为“根路径上下文”之前,我们(在 Continue 的帮助下)尝试了以下缩写:
ASCENT:用于节点遍历的抽象语法上下文提取 (Abstract Syntax Context Extraction for Node Traversal)
CLIMB:通过迭代分支方法查找上下文 (Context Lookup through Iterative Method of Branching)
UPROOT:向上路径检索以优化对象追踪 (Upward Path Retrieval for Optimized Object Tracing)
LEAF:词法环境获取框架 (Lexical Environment Acquisition Framework)
BRANCH:分层自底向上检索抽象节点上下文 (Bottom-up Retrieval of Abstract Node Contexts Hierarchically)
STEM:语法树探索方法 (Syntax Tree Exploration Method)
TRUNK:树协调以实现向上节点知识 (Tree Reconciliation for Upward Node Knowledge)
CANOPY:通过节点优化路径获取上下文成果 (Context Acquisition through Node Optimization Pathing Yield)
ROOTS:树语义的递归获取 (Recursive Obtainment Of Tree Semantics)
ARBOR:基于抽象表示的对象解析 (Abstract Representation Based Object Resolution)