
是时候收集关于你如何构建软件的数据了

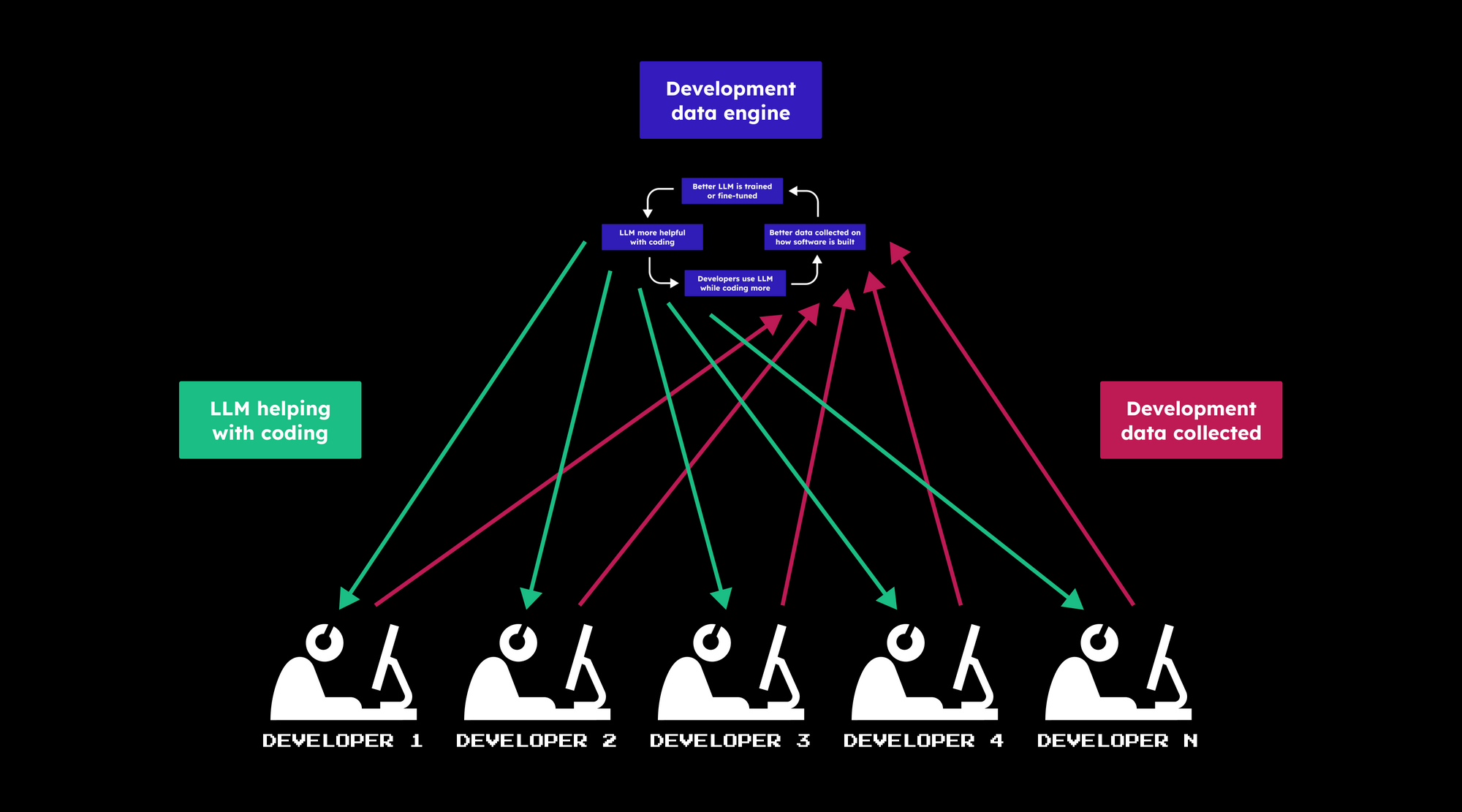
下一代开发者使用LLM取代Google + Stack Overflow
下一代开发者正在用Google + Stack Overflow取代大型语言模型(LLM),正如上一代开发者用Google + Stack Overflow取代了参考手册一样。那些在这种转型中能够留住和吸引开发者的组织将会
- 首先,了解他们的开发者如何使用LLM,并通过收集开发数据——关于他们的组织如何构建软件的数据——来证明使用LLM的投资回报率(ROI)
- 然后,利用这一基础建立一个开发数据引擎——这是一个持续的反馈循环,确保LLM总是拥有最新信息并遵循他们偏好的代码风格
通过证明LLM的投资回报率(ROI)来增加LLM预算的工程组织将能留住他们的顶尖开发者。当新的有才能的开发者在选择组织时,一个重要因素将是可用的LLM的质量。开发者会加入并留在那些通过持续改进的LLM获得赋能的地方——这些模型了解他们最新版本的代码库、项目、风格、最佳实践和技术栈。
首批意识到需要更好数据的组织是那些出于隐私和安全考虑而不使用LLM API的组织。他们正在自己的基础设施上部署开源LLM,这些模型最初的帮助程度远低于GPT-4,需要大幅改进。但即使是使用OpenAI的组织也面临着争取预算和数据过时的问题(例如,GPT-4不知道某个库的v3版本,因为它是在2021年11月发布的)。
您的组织需要收集关于您如何构建软件的数据
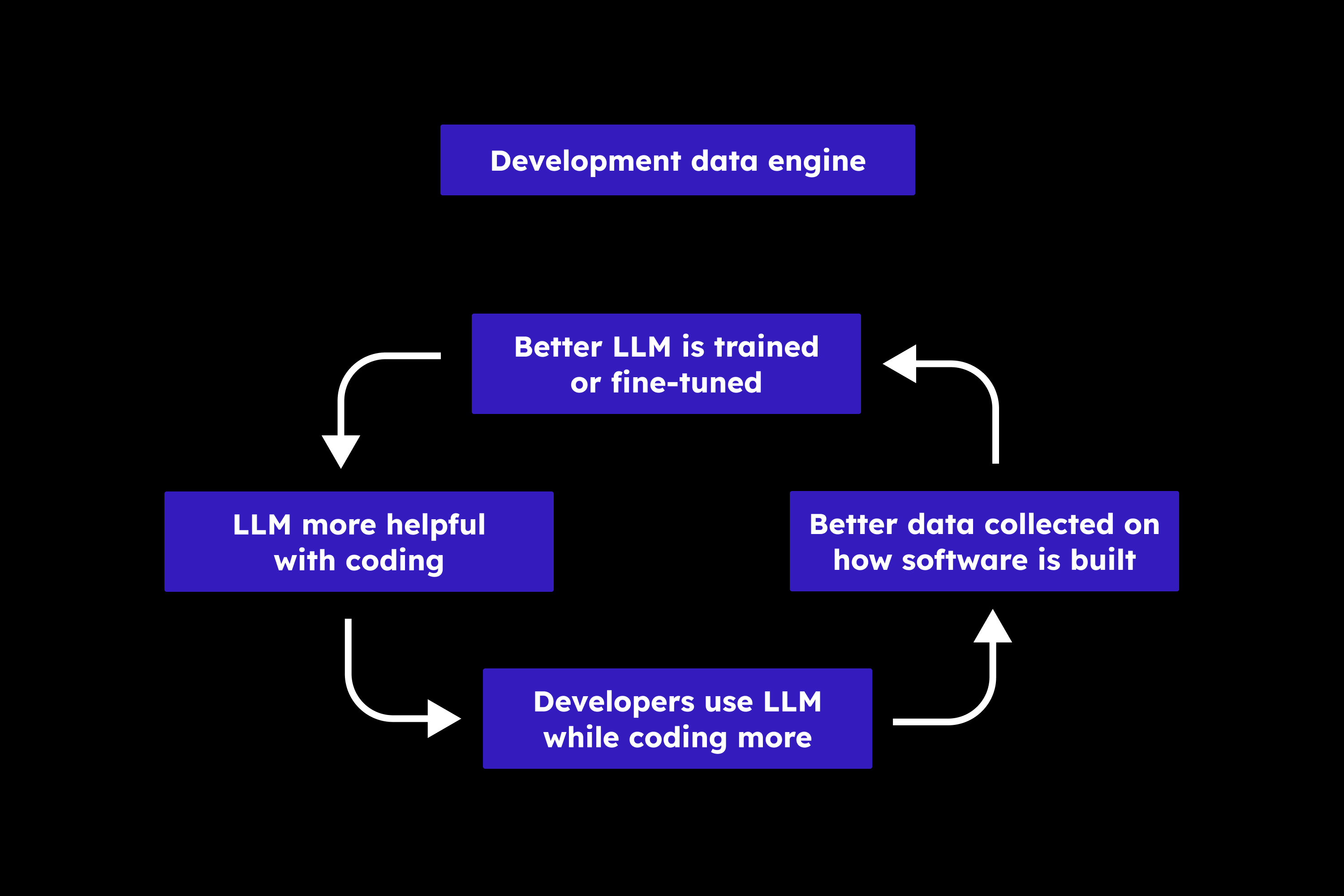
为了理解和扩展您的团队对LLM的使用,您需要收集关于您的组织如何构建软件的数据。您已经收集了大量数据:源代码、Git版本、问题/工单、PR/MR、讨论、日志等。这些数据对于训练首批具备编码能力的LLM至关重要。然而,这些数据更多地是关于构建了什么,而较少关于如何构建的。
要让LLM对您的开发者更有帮助,您需要收集更好的数据来了解Git提交之间发生了什么。现有数据通常缺失三个关键方面
- 开发者完成任务的逐步过程
- 开发者在每个步骤中决定做什么所使用的上下文
- 解释步骤背后原因的自然语言
好消息是,作为LLM辅助开发的副产品,此类数据已经在被创建。假设您的团队中有一位开发者,Hiro。为了获得建议,Hiro需要收集上下文(例如代码、文档等)并将其提供给LLM。随着Hiro和LLM的交互,他们将使用代码和自然语言的混合方式,迭代地完成当前任务。这些数据与Hiro最终提交的代码结合起来,提供了关于软件如何构建的丰富描述。
坏消息是,几乎所有开发者都在通过Copilot和ChatGPT使用LLM,这意味着除了GitHub和OpenAI之外,基本上没有人收集这些数据。当Hiro在Copilot建议后是否按下Tab键,或者当Hiro决定是否复制ChatGPT生成的代码时,这都会向这些产品发出信号,告诉它们将来应该多做些什么或少做些什么。即使Hiro之后编辑了代码,建议生成内容与最终状态之间的差异也可以作为信号使用。
关于如何最好地捕获、组织和应用这些开发数据以创建更有帮助的LLM,仍有许多未决问题,但很明显,收集像Hiro这样的开发者的隐式反馈来驱动一个开发数据引擎是关键。感谢个人的辛勤工作,他们的数据可以用来改进LLM,使整个团队受益。
Continue帮助您自动收集这些数据
在Continue,我们的使命是加速创造优秀的软件。但优秀对每个工程团队来说意味着不同的东西。
这就是为什么我们正在构建一个开源的编码自动驾驶仪,它允许您自动收集您的开发数据。根据这些数据,您可以计算LLM的投资回报率(ROI)。您可以更好地了解是什么让您的开发者感到沮丧。并且您可以改进模型来帮助他们克服这些挑战。
我们正在与有远见的组织合作,帮助他们建立自己的开发数据引擎。我们首先帮助他们提取、加载和转换他们的数据,以便他们能够了解开发者目前如何使用LLM,并为将来改进LLM打下基础。如果您有兴趣与我们合作,请发送电子邮件至data@continue.dev。
如果您喜欢这篇博文,并希望将来阅读更多关于DevAI——这个由借助LLM构建软件的人组成的社区——的文章,请在此加入我们的月度新闻通讯这里。