
使用 Relace 即时应用

特邀作者 Eitan Borgnia
像 Claude 3.7 这样的前沿模型正变得强大得令人难以置信,但它们也很慢且昂贵。它们的文本生成速度约为每秒 100-200 个 token,每百万输出 token 的成本可能高达 15 美元。
当您使用前沿模型来对您的代码库进行修改时,您通常会为有价值的更改和未更改的部分支付高昂的费用。即时应用正是关于分离这些关注点——使用重量级前沿模型生成新的代码段,然后使用轻量级应用模型将新的部分合并到旧的代码中。
让我们来看看 Relace 即时应用模型背后的理念,以及为什么它值得在您的 Continue 模型中心占有一席之地。
处理大型语言模型的“懒惰”行为
经过指令微调以扮演助手角色的模型,在代码生成任务中以“懒惰”著称。大型语言模型倾向于用诸如 // ... keep rest of code unchanged 的注释来替换大段未更改的代码,而不是写出完整的代码。这种行为源于 Stack Overflow 等网站上的训练数据特性,以及对输出序列长度的严格限制(通常为 8192 个 token)。
当主要工作流程涉及在 ChatGPT Web UI 之间复制/粘贴代码时,这令人烦恼,但对于自动化代理编码系统来说,这完全是一个障碍。当然,您总是可以在提示中对模型“大喊”一些类似这样的话:不要截断代码,否则您将受到惩罚。这可能会奏效,特别是对于现代模型,但这仍然是对资源的低效利用。
相反,我们可以利用这种“懒惰”行为,通过训练一个更小、速度快得多的大型语言模型来将截断的编辑合并到原始代码中。[1]
为什么合并很困难?
一个自然的问题是:为什么我们甚至需要一个大型语言模型来执行合并——我们难道不能编写一个算法来确定性地合并那些“懒惰”的大型语言模型输出吗?
这里有一个例子,说明为什么编写一个通用的算法来处理这个问题很困难。假设我们在处理身份验证的文件中有一个以下登录函数。
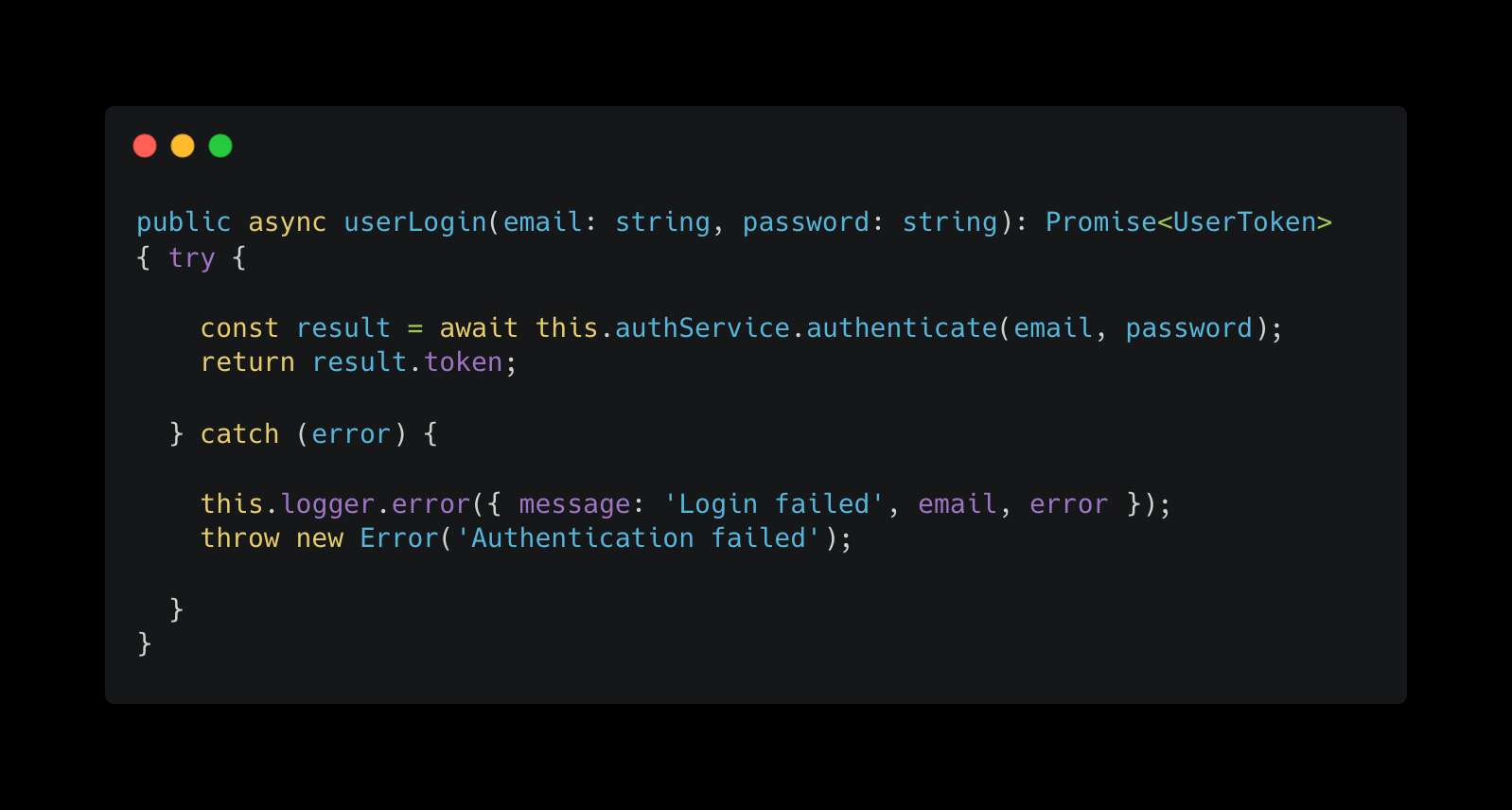
假设用户提示前沿模型:“将 userLogin 重命名为 customerLogin,并在允许客户登录之前验证验证码是否通过。”
Claude 给出的相应编辑片段可能看起来像这样。
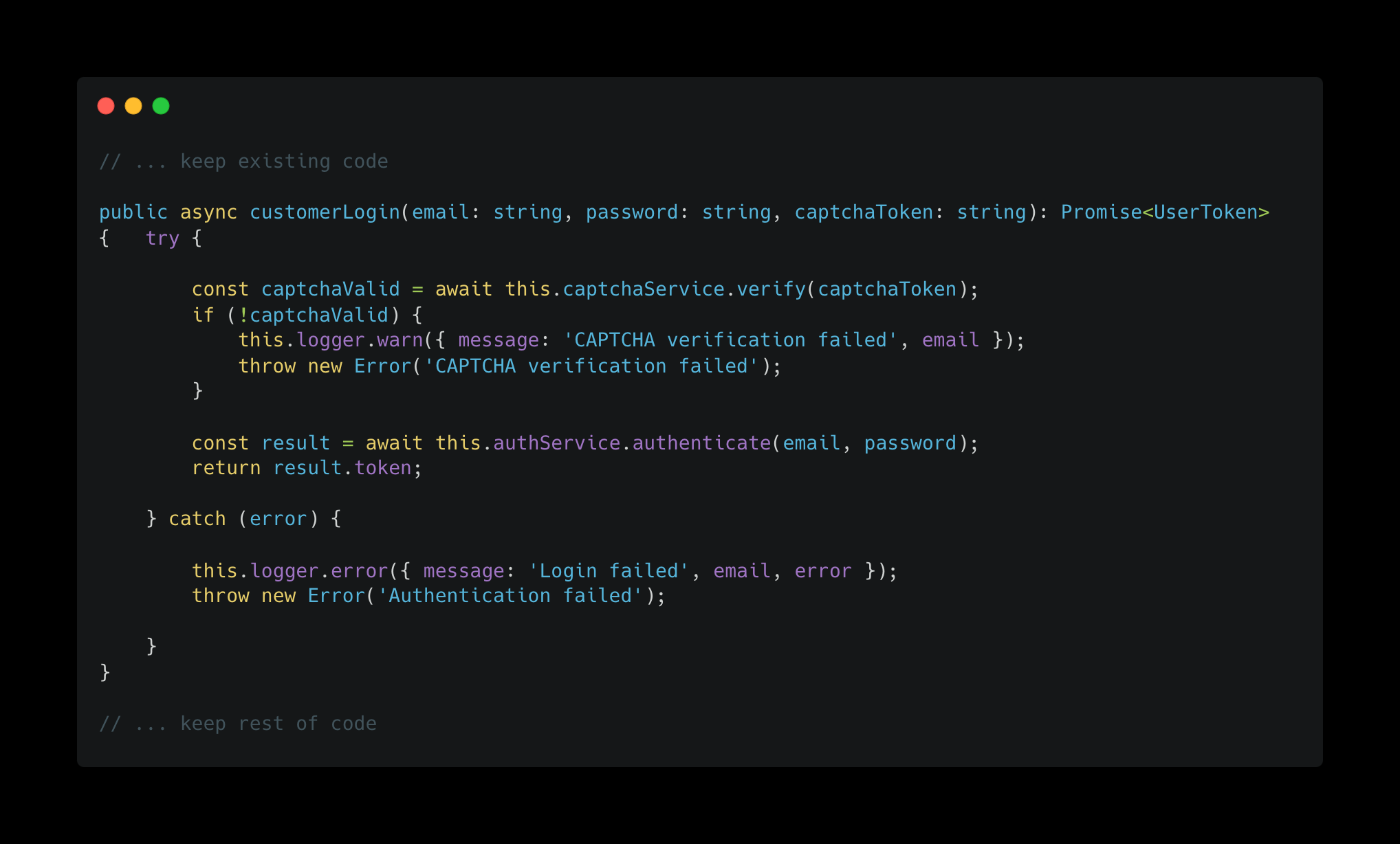
在这种情况下,您可以看到编写一个能够正确地将 userLogin 替换为 customerLogin 的通用算法所面临的挑战。除了函数体之外,函数名也发生了变化,大多数简单的合并算法最终会将 customerLogin 添加为一个新函数。
理论上,您可以在提示中要求模型在注释中包含必要的信息,从而使确定性合并成为可能。然而,这开始进入了结构化差异格式的领域,而这些格式本身也存在一系列挑战。
大型语言模型不习惯处理差异(Diffs)
有大量证据表明,当大型语言模型被迫同时考虑正确格式化输出时,它们生成的代码质量会降低。Aider 对结构化为 JSON 的输出进行了全面的研究,一个台湾研究小组调查了多种不寻常格式的影响。
一种减少编辑 token 预算的常见策略是使用搜索/替换或 uDiff 格式,然后可以进行确定性合并。问题在于前沿大型语言模型并没有针对这些结构化格式进行明确优化。Aider 的确有一些证据表明,uDiff 格式在预训练中遇到的次数足以在代码生成上保持性能。然而,很明显模型更喜欢不那么严格的“懒惰”格式,并且生成得更可靠——当切换到“懒惰”输出 + 应用时,搜索/替换方法的平均失败率从 >10% 下降到 <2%。
此外,这些结构化差异格式在 token 方面仍然相对低效。使用 uDiff 明确指定所有添加/删除的行,或者在搜索/替换中编写查找块,所需的 token 数量比“懒惰”输出多 1.5-2 倍。
通过利用模型的自然倾向——生成“懒惰”编辑,并使用来自专业应用模型的薄层智能,我们可以持续获得更高质量、更快、更廉价的结果。
Relace 即时应用
Relace 的即时应用模型是在包含初始代码、“懒惰”编辑片段和正确合并的最终代码的大型数据集上训练的,涵盖数十种常见的编程语言。在训练过程中遇到的各种各样的“懒惰”大型语言模型输出使其在生产环境中对边缘情况非常鲁棒,准确率约为 98%。
它使用优化的推测解码算法进行部署,以实现超过每秒 2000 个 token 的速度,并且随着每个版本的发布而不断改进。您可以在我们 10 月份关于即时应用的原始文章中阅读更多关于推测解码的信息。
此外,想要体验模型并查看它能够执行的一些合并示例,请访问 app.relace.ai 的 playground。祝您使用愉快!
[1] 2022 年末和 2023 年初较弱的语言模型以一种更具问题的方式表现出“懒惰”——它们会完全忽略实现重要函数。此处我们指的是更强大大型语言模型的现代“懒惰”行为,即模型不会为未更改的部分编写完整代码。