
面向软件工程师的代码 LLM 基准测试介绍

研究人员使用基准测试来评估和比较 LLM 的相对性能。虽然没有替代方法可以取代您亲自在编码时尝试 LLM 以找出哪一个最适合您,但基准测试和流行度排名可以帮助确定哪些 LLM 值得尝试。
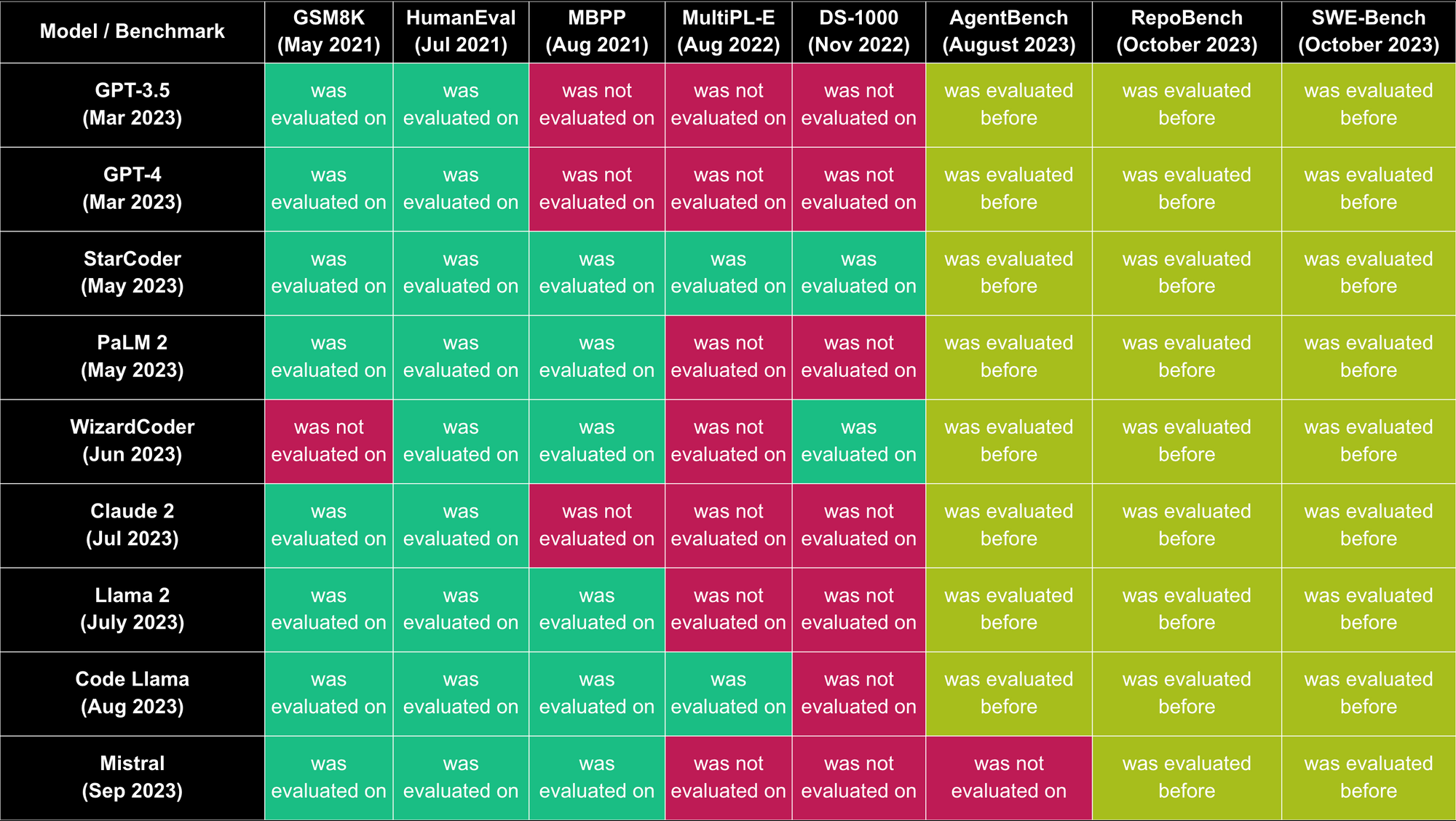
截至2023年10月,最流行的商业代码 LLM 包括 GPT-4、GPT-3.5、Claude 2 & Palm 2。 最流行的开源代码 LLM 包括 Code Llama、WizardCoder、Phind-CodeLlama、Mistral、StarCoder & Llama 2。下面我们将为您介绍这些模型的创建者在其论文中使用的基准测试以及其他一些代码基准测试。
三个最常见的基准测试
1. HumanEval
创建者: OpenAI
发布时间: 2021年7月
评估对象: 九个流行的代码 LLM——GPT-3.5(2023年3月)、GPT-4(2023年3月)、StarCoder(2023年5月)、PaLM 2(2023年5月)、WizardCoder(2023年6月)、Claude 2(2023年7月)、Llama 2(2023年7月)、Code Llama(2023年8月)和 Mistral(2023年9月)
动机: 代码 LLM 通常在 GitHub 的很大一部分数据上进行训练,而 GitHub 已包含来自各种来源的问题解决方案。例如,有十多个包含 Codeforces 问题解决方案的公共仓库,这些仓库构成了在 HumanEval 发布前不久发布的 APPS 数据集的一部分。为了解决这个问题,HumanEval 的所有问题都是人工编写的,而不是从现有来源复制的。
描述: HumanEval 是一个用于衡量从文档字符串合成程序的函数正确性的基准测试。它包含 164 个 Python 编程问题。每个问题包括函数签名、文档字符串、函数体和多个单元测试,平均每个问题有 7.7 个测试。HumanEval 数据集中的编程任务评估语言理解、推理、算法和简单的数学能力。
论文网址: https://arxiv.org/abs/2107.03374
数据集网址: https://github.com/openai/human-eval
2. GSM8K
创建者: OpenAI
发布时间: 2021年9月
评估对象: 八个流行的代码 LLM——GPT-3.5(2023年3月)、GPT-4(2023年3月)、StarCoder(2023年5月)、PaLM 2(2023年5月)、Claude 2(2023年7月)、Llama 2(2023年7月)、Code Llama(2023年8月)和 Mistral(2023年9月)
动机: LLM 在许多任务上可以媲美人类的表现,但它们在稳健地执行多步数学推理方面仍然存在困难。
描述: GSM8K 是一个包含 8.5K 个由人类作者创建的高质量小学数学问题的数集。这些问题需要 2 到 8 步来解决,解题主要涉及使用基本算术运算(+ - / *)执行一系列基本计算以得出最终答案。一个聪明的初中生应该能够解决所有问题。值得注意的是,这并非代码基准测试,但几乎所有流行的代码 LLM 的创建者都使用它进行了评估。
论文网址: https://arxiv.org/pdf/2110.14168.pdf
数据集网址: https://github.com/openai/grade-school-math
3. MBPP
创建者: Google
发布时间: 2021年8月
评估对象: 六个流行的代码 LLM——StarCoder(2023年5月)、PaLM 2(2023年5月)、Claude 2(2023年7月)、Llama 2(2023年7月)、Code Llama(2023年8月)和 Mistral(2023年9月)
动机: MBPP 与 HumanEval 基准测试相似,但在提示的格式上有所不同。它始终包含三个输入/输出示例,以 assert 语句的形式编写。相比之下,HumanEval 的输入/输出示例在数量和格式上有所变化,更贴近现实世界的软件。
描述: Mostly Basic Programming Problems (MBPP) 数据集包含 974 个编程任务,旨在供入门级程序员解决。它旨在衡量这些模型根据自然语言描述合成短 Python 程序的能力。该数据集由大量众包问题和少量由作者编辑并手动验证的问题组成。每个问题通常包含三个测试用例。
论文网址: https://arxiv.org/abs/2108.07732
数据集网址: https://github.com/google-research/google-research/tree/master/mbpp
一些值得注意的提及
4. MultiPL-E
创建者: 东北大学、韦尔斯利学院、奥伯林学院、史蒂文斯理工学院、微软研究院和 Roblox
发布时间: 2022年8月
评估对象: 两个流行的代码 LLM——StarCoder(2023年5月)和 Code Llama(2023年8月)
动机: 将 HumanEval 基准测试和 MBPP 基准测试扩展到包含多种编程范式和流行度的 18 种语言
描述: MultiPL-E 是一个用于将单元测试驱动的代码生成基准测试翻译成新语言的系统,以创建第一个大规模多语言代码生成基准测试。
论文网址: https://arxiv.org/abs/2208.08227
数据集网址: github.com/nuprl/MultiPL-E
5. DS-1000
创建者: 香港大学、北京大学、斯坦福大学、加州大学伯克利分校、华盛顿大学、Meta AI 和卡内基梅隆大学
发布时间: 2022年11月
评估对象: 两个流行的代码 LLM——StarCoder(2023年5月)和 WizardCoder(2023年6月)
动机: 与之前的工作相比,这些问题反映了多样化、现实和实用的用例,因为它们是从 StackOverflow 收集的。它们经过轻微修改,以主动防止记忆。
描述: DS-1000 是一个代码生成基准测试,包含一千个涵盖七个 Python 库(如 NumPy 和 Pandas)的数据科学问题。
论文网址: https://arxiv.org/abs/2211.11501
数据集网址: https://github.com/xlang-ai/DS-1000
几个最近发布的基准测试
6. AgentBench
创建者: 清华大学、俄亥俄州立大学和加州大学伯克利分校
发布时间: 2023年8月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 在交互式环境中评估 LLM 作为智能体执行具有挑战性任务的需求迫切。
描述: AgentBench 是一个多维度的演进式基准测试,目前包含 8 个不同的环境,用于评估 LLM 作为智能体在多轮开放式生成设置中的推理和决策能力。
论文网址: https://arxiv.org/pdf/2308.03688.pdf
数据集网址: https://github.com/THUDM/AgentBench
7. SWE-Bench
创建者: 普林斯顿大学和芝加哥大学
发布时间: 2023年10月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 语言模型的发展速度已超出我们有效评估它们的能力,但对其未来发展而言,研究其能力的边界至关重要。SWE-Bench 将现实世界的软件工程视为评估下一代语言模型的一个丰富、可持续且具有挑战性的试验平台。
描述: SWE-Bench 是一个评估框架,包含从 12 个流行 Python 仓库的真实 GitHub issue 和相应的 pull request 中提取的 2,294 个软件工程问题。给定代码库以及待解决问题的描述,语言模型的任务是编辑代码库以解决该问题。解决 SWE-Bench 中的问题通常需要同时理解和协调跨多个函数、类甚至文件的更改,要求模型与执行环境交互、处理极长的上下文并执行远超传统代码生成的复杂推理。
论文网址: https://arxiv.org/abs/2310.06770
数据集网址: https://github.com/princeton-nlp/SWE-bench
8. RepoBench
创建者: 加州大学圣迭戈分校
发布时间: 2023年10月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 当前的基准测试主要关注单文件任务,在更复杂、现实世界的多文件编程场景方面存在评估空白。
描述: RepoBench 是一个专门为评估仓库级代码自动完成系统设计的新基准测试。RepoBench 支持 Python 和 Java,包含三个相互关联的评估任务:RepoBench-R(检索)、RepoBench-C(代码完成)和 RepoBench-P(流水线)。每个任务分别衡量系统从其他文件检索最相关代码片段作为跨文件上下文的能力,利用跨文件和文件内上下文预测下一行代码的能力,以及处理需要检索和下一行预测相结合的复杂任务的能力。RepoBench 旨在促进更全面的性能比较,并鼓励自动完成系统的持续改进。
论文网址: https://arxiv.org/abs/2306.03091
数据集网址: https://github.com/Leolty/repobench
一些多语言 基准测试
10. HumanEval-X
创建者: 清华大学、智谱AI 和华为
发布时间: 2023年3月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 原始 HumanEval 数据集仅支持 Python
描述: HumanEval-X 基准测试在 HumanEval 的基础上,人工用 C++、Java、JavaScript 和 Go 重写了解决方案
论文网址: https://arxiv.org/abs/2303.17568
数据集网址: https://github.com/THUDM/CodeGeeX
11. MBXP / Multilingual HumanEval
创建者: AWS AI Labs
发布时间: 2023年3月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 原始 MBPP 和 HumanEval 数据集仅支持 Python
描述: 这些数据集涵盖了超过 10 种编程语言,使用一个可扩展的转换框架生成,该框架将原始 Python 数据集中的提示和测试用例转译为目标语言中的相应数据
论文网址: https://arxiv.org/abs/2210.14868
数据集网址: https://github.com/amazon-science/mxeval
12. BabelCode / TP3
创建者: Google 和纽约大学
发布时间: 2023年5月
评估对象: 在论文中未被任何流行的代码 LLM 使用
动机: 当前用于评估神经代码模型的基准测试仅关注一小部分编程语言,排除了 Go 或 Rust 等许多流行语言。
描述: BabelCode 框架可用于对任何基准测试在任何语言中进行基于执行的评估,从而可以对模型在内存、运行时和单个测试用例结果方面的定性性能进行新的研究。Translating Python Programming Puzzles (TP3) 是一个基于 Python Programming Puzzles 基准测试的代码翻译数据集。
论文网址: https://arxiv.org/abs/2302.01973
数据集网址: https://github.com/google-research/babelcode
另外三个基准测试
13. ARCADE
创建者: Google
发布时间: 2022年12月
评估对象: 一个流行的代码 LLM——PaLM 2(2023年5月)
动机: 计算型笔记本(例如 Jupyter 笔记本)是数据科学家进行数据整理和分析任务的普遍交互式计算环境。ARCADE 旨在衡量 AI 结对编程器在此类任务中自动合成程序的能力,输入是用户的自然语言 (NL) 意图。
描述: ARCADE 是一个在数据科学笔记本中使用 pandas 数据分析框架的 1,082 个代码生成问题的基准测试,其特点是来自同一笔记本的多轮自然语言到代码问题,需要模型理解丰富的多模态上下文,例如现有笔记本单元及其执行状态以及之前的交互轮次。
论文网址: https://arxiv.org/pdf/2212.09248.pdf
数据集网址: https://github.com/google-research/arcade-nl2code
14. APPS
创建者: 加州大学伯克利分校、芝加哥大学、伊利诺伊大学香槟分校和康奈尔大学
发布时间: 2021年5月
评估对象: 一个流行的代码 LLM——Code Llama(2023年8月)
动机: 与更受限制的设置中的先前工作不同,APPS 衡量模型接收任意自然语言规范并生成满足此规范的 Python 代码的能力。
描述: APPS 包含 10,000 个问题,难度从简单的单行解决方案到重要的算法挑战不等。类似于公司评估候选软件开发人员的方式,他们通过在测试用例上检查生成的代码来评估模型。
论文网址: https://arxiv.org/pdf/2105.09938v1.pdf
数据集网址: https://github.com/hendrycks/apps
15. HumanEval+
创建者: 伊利诺伊大学香槟分校和南京大学
发布时间: 2023年5月
评估对象: 一个流行的代码 LLM——WizardCoder(2023年6月)
动机: 现有的编程基准测试在数量和质量上可能有限,无法完全评估生成的代码的功能正确性。
描述: 使用 EvalPlus 框架,HumanEval 通过自动测试输入生成器(由 LLM 和变异策略驱动)新生成了大量测试用例。HumanEval+ 将 HumanEval 的测试用例数量扩展了 81 倍。
论文网址: https://arxiv.org/abs/2305.01210
数据集网址: https://github.com/evalplus/evalplus
排行榜
Hugging Face 维护着大型代码模型排行榜,它根据 HumanEval 和 MultiPL-E 评估显示开源代码 LLM 的实时排名。
结论
如您所见,其中许多评估都相当简单。在这些评估中表现出色并不意味着我们“解决了编码问题”。我们需要推动更具雄心、更好的仓库级基准测试,以便 LLM 在我们编码时能提供更多帮助。值得注意的是,许多模型不开源其训练数据,因此存在数据泄露问题的担忧,即评估数据集可能已包含在训练数据中。
最终,基准测试不会告诉您关于语言模型所需了解的一切,但它们是了解最新模型的好方法。如果一个新的 LLM 横空出世,在排行榜上遥遥领先,这并不一定意味着它是一个出色的模型,但它是一个很好的迹象,表明您可能想尝试一下!
如果您喜欢这篇博客文章并想将来阅读更多关于 DevAI(借助 LLM 构建软件的社区)的内容,请这里订阅我们的月度时事通讯。